SceneVerse contains 3D scenes curated from diverse existing datasets of both real and synthetic environments. Harnessing the power of 3D scene graphs and LLMs, we introduce an automated pipeline to generate comprehensive and high-quality language for both object-level and scene-level descriptions. We additionally incorporate the most extensive human-annotated object referrals to date, providing new training sources and benchmarks in this field.


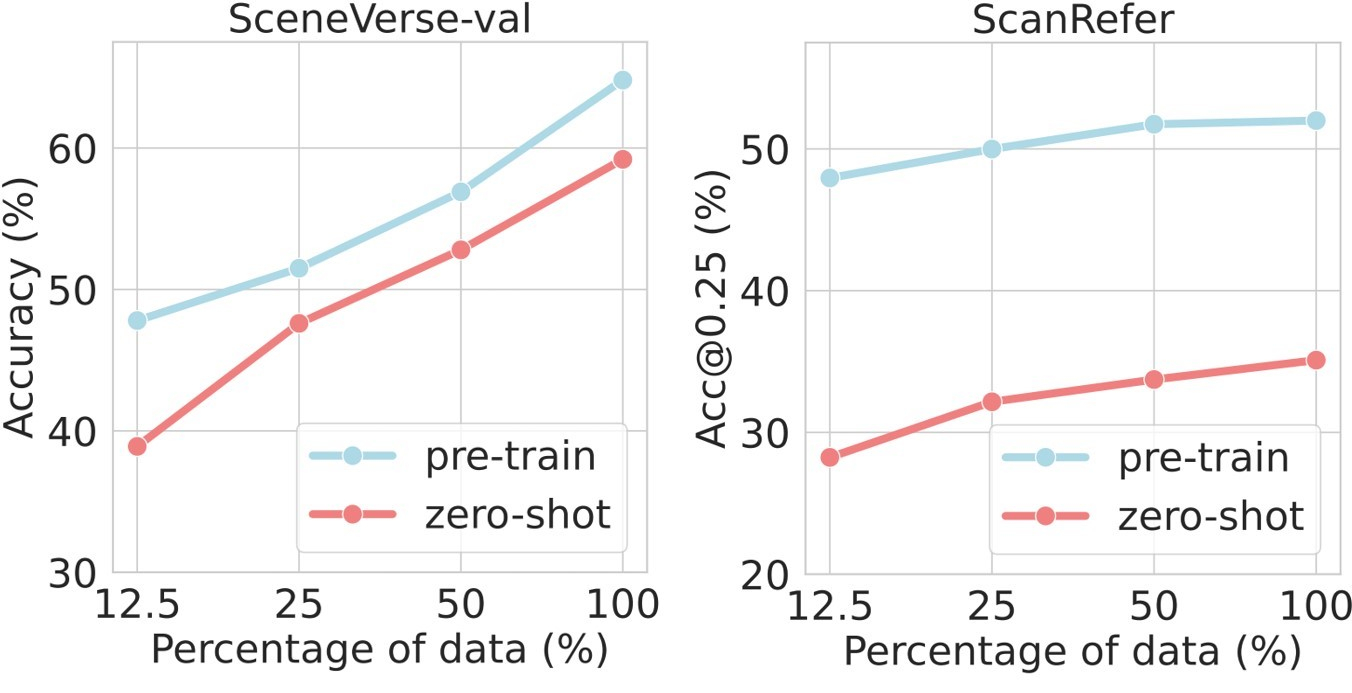
Grounded Pre-training for Scenes (GPS) is a transformer-based model trained with multi-level contrastive losses for aligning 3D scenes and texts. We echo the language descriptions collected to form scene-language pairs at both object-level, referral-object-level, and scene-level for contrastive objectives in GPS. The resulting model shows scaling effect in pre-train/fine-tune and zero-shot settings.
To use the interactive data explorer, first select from the available scenes in the select bar and then choose a type of language description
available in the buttons. Click the "Scene Caption" button for scene captions. To visualize other types, check the corresponding box and double click an object in the scene for visualizing
the results. All available objects could be found according to the segmentation visualization. Best viewed on monitors.
Control: Click + Drag = Rotate Ctrl + Drag = Translate Scroll Up/Down = Zoom In/Out Double Click = Select Object
@inproceedings{jia2024sceneverse,
title={Sceneverse: Scaling 3d vision-language learning for grounded scene understanding},
author={Jia, Baoxiong and Chen, Yixin and Yu, Huangyue and Wang, Yan and Niu, Xuesong and Liu, Tengyu and Li, Qing and Huang, Siyuan},
booktitle={European Conference on Computer Vision (ECCV)},
year={2024}
}